Most people involved with condition monitoring view the service they provide as indispensable. They are in a unique position to detect the onset of equipment failure thus ensuring that the company does not incur the consequences associated with catastrophic failure. It takes tremendous skill, experience and courage to detect the earliest signs of failure, determine what is going wrong, and make the appropriate recommendation. The only problem is that not everyone in the organization understands the value of that service. And it is not always their fault.
It is not their fault because most condition monitoring people do not actively promote the benefits of their program, and they do not educate people about what they are doing, how they do it, and why they do it.
And it is not their fault because many condition monitoring programs do not provide as much value as they should…
In this article we will explore what the goals of the condition monitoring program should be, how the condition monitoring program can be structured to deliver the greatest service, and how the condition monitoring team should publicize the value of their indispensable service.
What drives your program? Do you have a tier-one, tier-two, or tier-three program?
In the author’s experience, condition monitoring programs normally have one of three driving forces and thus can be categorized into three tiers. Most are tier-one. Some are tier-two. And not nearly enough are tier-three.
What is a tier-one program?
A tier-one program is primarily focused on detecting terminal failure. The goal is to test as many machines as possible to provide an early warning of failure. For vibration analysis programs, the focus is often bearing fault detection. But root causes such as misalignment, unbalance, looseness, and resonance will also be detected and reported only if the severity is high enough. The condition monitoring team will commonly see the same machines develop the same faults over and over again, but little real action is taken to avoid those failures for a variety of reasons.
Often tier-one programs are not part of an asset strategy. It is not a structured condition-based maintenance program; unnecessary time-based PM’s are still performed. The aim is to be forewarned of impending failure – they are just practicing reactive maintenance with a slightly longer time to react…
In a weak tier-one program the warnings about failures come late so everything is urgent, plus the recommendations are not very clear.
In a strong tier-one program, warnings come much earlier and the team verifies that their assessment of the fault condition (fault type and severity) was accurate, plus they will keep metrics related to schedule compliance. A good tier-one program will also utilize time waveform analysis, phase analysis, motor current analysis, wear particle analysis, and other condition monitoring technologies to provide the earliest and most accurate diagnosis and recommendation.
Tier-one programs deliver value – without question. But is there more than can be achieved? Absolutely.
What is a tier-two program?
A tier-two program includes the detection and elimination of root causes. The condition monitoring team will detect root causes such as misalignment, unbalance, resonance, and poor lubrication, and do its utmost to ensure that those root causes are eliminated.
In a tier-two program the analysts will get involved in certain maintenance tasks, like lubrication, balancing and shaft alignment, to ensure that tasks are performed with precision.
They will also perform QA/QC. They will test machines after repair/restoration/replacement work has been completed to ensure that no new faults or root causes were induced during that work. They will also be involved in acceptance testing; ensuring that all new and overhauled equipment is in “perfect” condition, and if it isn’t, the equipment will be rejected until it passes.
Two things make it difficult to become a tier-two program. First, they don’t have time to test all of the machines and perform all of the additional analysis in order to eliminate the root causes. Second, they work in an organization that does not fully believe in the condition-based maintenance philosophy, or the benefits of precision and proactive maintenance. As a result they struggle to keep up with the fault conditions detected and thus do not place a high priority on eliminating root causes. (Little do they know that if they eliminated the root causes, the volume of work would be reduced.)
The best way to overcome those challenges is to strive to become a tier-three program.
What is a tier-three program?
A tier-three program is a strategic, structured program designed to deliver the greatest value to the organization. It strives to help the business achieve its goals. A tier-three program understands the value of reliability improvement and it delivers clear, actionable information about the health of the equipment and the corrective action that must be taken.
A tier-three program executes true condition-based maintenance (not just condition monitoring) based on the asset strategy which is based on business needs (mitigating risks and achieving targets). The aim is to detect failure and root causes, and it implements root cause failure analysis (RCFA) in order to eliminate future failure and to improve the asset strategy.
How do you become a tier-three condition monitoring program?
It is almost impossible to deliver the greatest value unless you really understand the goals and priorities of the business. If we had unlimited resources we would do our utmost to detect every fault and eliminate every root cause. But on the one hand, you probably don’t have unlimited resources. And on the other hand, you probably shouldn’t have unlimited resources because detecting every fault and eliminating every root cause cannot be justified.
The goal therefore is to design the optimal program that strikes the right balance between the costs to implement the program and the benefits achieved. While the benefits of condition monitoring are often focused on risk mitigation (safety, environment, costs, downtime, etc.) it is critically important that there is due consideration given to the ways in which it can help the business achieve its goals (capacity, throughput, quality, reduction of process interruptions, yield, dependability, cost & waste reduction, etc.).
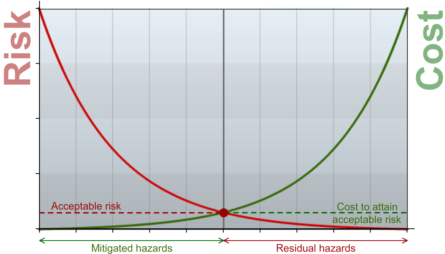
What does the company value?
The first stage is to step back and ask why the company employs you and pays for the instruments and training. The obvious answer is to avoid failure and thus the consequences of failure. But it is worth digging deeper.
Based on the company ownership, whether the company produces a product or provides a service, its position in the market (high-cost leader, low-cost competitor, etc.), the age of the plant, and many other factors, it is important to recognize that the key drivers and primary risks can vary, and thus our priorities can change – we should prioritize between:
- Quality
- Uptime and throughput
- Equipment failure and secondary damage
- Safety (employee and customer)
- Environmental protection
- Cost reduction
- Life extension
- Brand, reputation and customer satisfaction
We call this process a “business process review”. It helps you prioritize your condition monitoring, reliability and maintenance strategy and it can help justify the reliability improvement program (at the commencement and on an ongoing basis).
How do you use this information?
The primary way you use this information is to prioritize and justify your program. If you know which are your critical equipment (via a criticality ranking), and you understand failure modes, and lead time to failure, then you can develop an asset strategy that combines condition-based maintenance, time-based proactive and corrective maintenance, and run-to-failure when the other strategies cannot be justified. Utilizing criticality, and with an understanding of the failure modes and root causes, it is possible to prioritize which equipment is monitored, which are tested with multiple technologies, and how frequently tests should be performed.
What if you can’t test all the equipment you would like to test?
With the above prioritization you may conclude there are some machines you don’t have the resources to test, but you feel the criticality is high enough that they justify testing. If management won’t agree to additional resources, what should you do?
You could consider testing equipment less frequently, but then you are potentially putting critical equipment at risk. But if you have a good idea of an asset’s reliability, and management is willing to accept the higher risk, then this can be an acceptable approach.
You could consider utilizing fewer condition monitoring technologies. But as above, you have to consider this question carefully because you will be increasing your risk.
But there are three additional possibilities:
- If it can be justified, you could use on-line monitoring systems. That requires a capital outlay, but consumes fewer resources on an on-going basis and also reduces the risk of missing the signs of a fault condition.
- You could utilize operator driven reliability (ODR) – asking operators to perform basic tests to give you a warning if the health appears to change.
- You can look at ways to use automation to detect change in your data to avoid analyzing every piece of data collected. A lot of time can be wasted analyzing data that has not changed. Setting good alarm limits, ideally using statistics, can save a great deal of time. You could also consider automated diagnostic systems and predictive analytics.
How else can you improve the value of your service?
You need to provide information about the health of the equipment so that everyone with an interest can see what the status is, and what is being done about any equipment with poor health. Maintenance people need reports with actionable information, not vague comments about high vibration, spectral patterns, looseness, and other vague recommendations. They want to know what’s wrong, and how urgently they need to respond.
This is one of the biggest complaints that I hear about condition monitoring programs: inaccessible, confusing reports with too much data. This is your primary deliverable so it is critical it provides people with the information they need to make their key decisions.
How can you ensure people understand the value of your service?
In addition to providing actionable information, you need to constantly sell what you do. Tell management about the costs you have avoided and the risks you have averted. Save bearings and gears that have been removed from machines and keep them on display. Determine how your service helps to reduce risk and helps the business achieve its goals, and maintain and publicize KPIs that indicate how they have improved thanks to the condition monitoring (and reliability improvement) activities. You should see OEE improve, maintenance costs reduce, and the number of lost-time injuries go down.
At least annually you need to ensure that all plant and corporate management are aware of the benefits of your service, and what will happen if they remove your service – a return to the bad old days.
Conclusion
Condition monitoring can help a business become safer and more competitive. For the sake of the business you need to ensure that it is focused on the businesses most critical assets, it is part of a well-designed asset strategy, and that you provide actionable information. For your own sake, it is critical that you publicize the benefits of your program, especially to senior management.







