A copper mine site already had an extensive condition monitoring program in place. We went through their oil analysis reports regularly, sitting down with them and going through the possible faults.
Every mine site has several critical machines. On this site, the most critical was the semi-autogenous grinding (SAG) mill, which runs 24/7 with a full load. At the moment, because the life of the mine is limited, they are running at full production, occasionally overloading the mill. When the mill stops, the production cannot be recovered, and it is the only mill on the site.
The gearbox has been replaced several times in the past due to bearing and gear failures, so the mine wanted this piece of equipment to be monitored carefully to avoid expensive unexpected failures during the short time remaining for the mine.
Though we never failed to detect actual failures, there were other things going on: overheating, noise, etc. When those issues arose, we were called to the mine regularly (sometimes every second day) to check the equipment. Of course, this would happen at the most inconvenient times (holidays, weekends, when production was critical, etc.). This was expensive, and there was no guarantee someone would always be available to go. Therefore, the decision was made to install a permanent on-line monitoring system on the SAG mill.
We installed a monitoring system called KITE. It can manage various conditions and measure at different load speeds and in different directions. The mill is a fixed-speed machine, so we didn’t need any special inputs. The speed sensor was there to tell us if the mill had shut down. KITE is good with low-speed shaft monitoring, as it was primarily designed for wind turbines and is capable of producing data for slow-speed rotating equipment.
The monitoring system sits next to the electrical box of the mill and feeds the signal to the software, where we can view the data and give it to the customer. If an alarm is raised, we get an email or SMS notification. We got a lot of them initially because we had set the alarms low, but we then set them a bit higher.
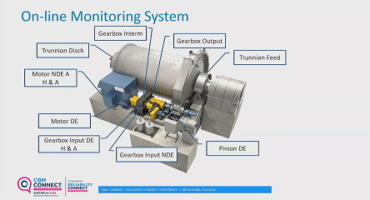
Initially, we only monitored the gearbox, and five sensors gave us all the signals we needed to measure gear mesh, bearings, etc. We later added three sensors to the motor (NDE horizontal and axial; DE horizontal). These were the locations of the five sensors on the gearbox: input DE horizontal and axial, input NDE horizontal (this is the bearing that often failed), intermediate NDE horizontal, and output DE horizontal. We also added a sensor to the pinion DE because there was an early fault in it we wanted to monitor. On the trunnion bearings, we added sensors with 500 mV/g. There was also a speed sensor to collect data only when the mill was running, but it became useful in letting us know when the mill shut down and what was going on then.
We installed the system on January 25, 2019. In March of that year, we detected a gearbox bearing fault; in April, a motor bearing fault just after replacement of the gearbox; and in August, a gearbox bearing failure.
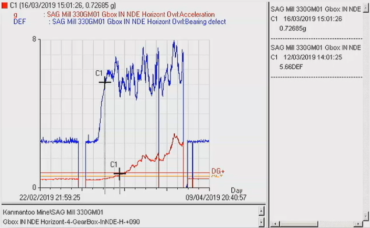
For the first bearing failure, we received an alarm on March 13. The main indication was the bearing defect factor (DEF). There was also an increase in acceleration levels; however, the increase level was much slower compared to the DEF. The two combined clearly indicated a bearing fault.
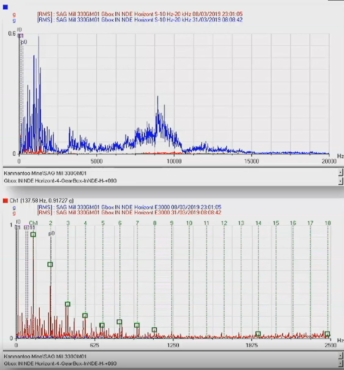
The spectra showed a clear bearing fault. The energy hump around 10 kHz was the first change in pattern. The modulation was typical for a bearing fault, and the sidebands were at the BPFI.
The inner race of the input shaft NDE bearing showed damage and cracks.
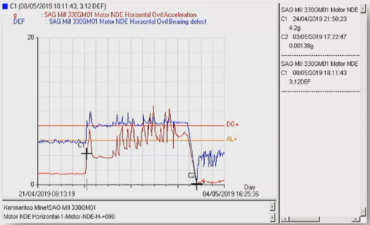
After they replaced the gearbox and bearings, on April 24, we received an alarm, although I didn’t think it was possible for something to be wrong already. Both the DEF and acceleration levels on the motor NDE showed a jump change. The levels were much higher than those previously experienced on the gearbox, especially the acceleration. We didn’t hesitate to recommend a replacement ASAP.
The spectral pattern was similar to the gearbox failure pattern, and it clearly showed an inner race fault with sidebands. This was a familiar pattern to us, and we immediately suggested the replacement.
The mill was shut down and the bearing replaced on May 7, about two weeks after the fault was detected. It had deteriorated significantly by that time.
Interestingly, on April 14 (surveys were taken every six weeks), no faults were detected. The spectra were normal. If we hadn’t been using the on-line system, who knows what could have happened? Perhaps someone would have heard the bearing making noise, or the bearing could have failed unexpectedly between surveys.
The bearing showed advanced damage on the inner race.
Nothing happened between April and August, but we received another alarm on August 5. Both the DEF and acceleration levels on the gearbox input shaft NDE bearing showed increase. These were the same indicators we’d seen previously, so the bearing was quickly replaced.
In conclusion, routine vibration analysis surveys are still a good and reliable tool to support predictive maintenance. However, for critical equipment, on-line monitoring is the best way to ensure faults are detected as soon as they occur. We have detected increased impacting, acceleration, lack of lubrication, looseness, etc., and have been able to prevent premature failures in this way. With an early warning, replacements can be planned well in advance, with minimum production losses and maintenance costs.







