
About the Author
AVT Reliability

Balancing cost reduction and efficiency improvement targets is a common source of frustration for maintenance and engineering managers. For facilities that operate continuously with no window for unplanned shutdowns, poor reliability and availability of machinery is far more serious, but even in factories with regular opportunities for maintenance, recovery can still be expensive and time consuming.
Reactive maintenance, also referred to as ‘run to fail’, is the most basic strategy but can result in significant downtime, reduced throughput and higher repair costs than proactive methods of maintenance. So, how challenging and rewarding is the journey from reactive to proactive maintenance?
The investment in moving to proactive maintenance involves planning and management with a necessary initial outlay of time and effort to make sure the program is sustainable. While reactive maintenance covers simply running equipment to the point of failure before acting, proactive maintenance can be subdivided into four further strategies, and time must be invested to uncover the optimum combination of these methods to improve availability and reliability. Of the four proactive maintenance strategies – breakdown maintenance, planned/preventative maintenance, condition based maintenance and design out – This often provides the greatest opportunity for cost savings and increased efficiency and asset reliability.
Condition based maintenance, also known as “predictive maintenance” is a maintenance strategy within which condition monitoring is the core approach. Measuring symptoms to uncover the causes of faults and prevent them becoming a regular occurrence. In order to implement this effectively, time must be invested in undertaking cost/benefit analysis as well as auditing and cataloguing the equipment on site in order to target the most important assets with the greatest potential for cost savings.
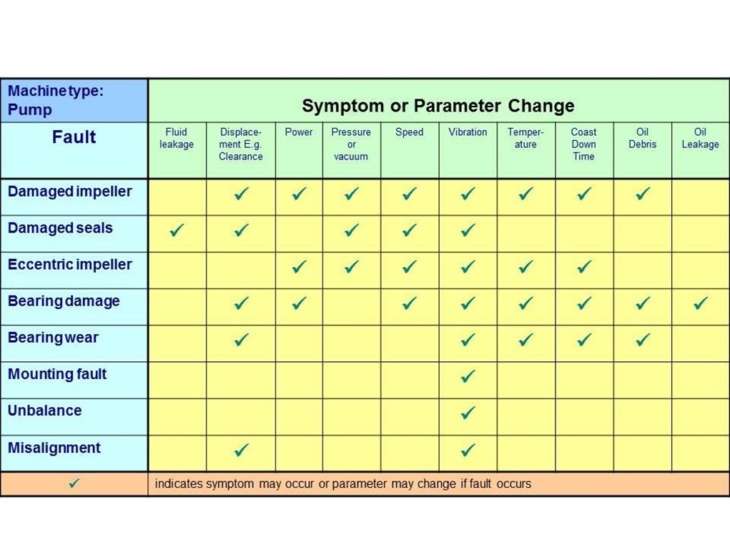
Only after this initial research has been completed or reviewed can a maintenance team begin to identify the parameters to be measured, and select measurement techniques and locations. Maintenance comprises a variety of techniques from straightforward visual inspections to thermal, vibration, ultrasonic and oil monitoring, all of which require specialist equipment and training to undertake. Selection will depend upon identifying symptoms and parameter changes to determine the fault, as shown in figure one. For example, worn bearings within a pump may result in displacement, vibration, temperature change, coast down time or oil debris. Rather than identifying a fault such as a damaged seal and simply replacing the component, effective monitoring uncovers the root cause, preventing reoccurrence and potentially solving other related faults as well.
Another area which must be considered is how quickly the fault develops, and when detection of the fault is possible. A typical fault may produce a number of symptoms as it progresses towards ultimate failure, all of which may be detectable and measureable but will present at different stages of fault development. For example, figure 2 shows a progression of an example fault where P = potential failure and F = failure. In this example, vibration was the earliest detectable parameter while a detectable temperature change occurred immediately before the failure, meaning that for this piece of equipment, heat sensing would be the least useful technique in preventing failure whereas vibration and oil monitoring are likely to flag up areas for concern as far as nine months in advance of a failure.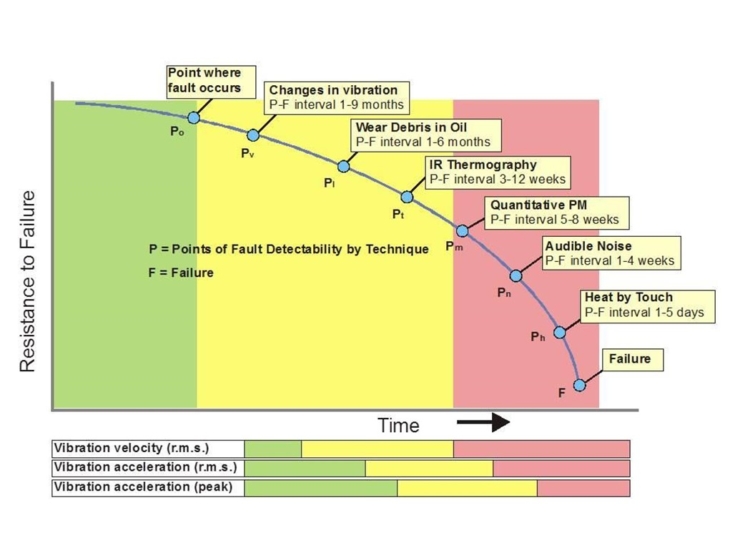
Setting suitable alert and alarm criteria is therefore also critical, allowing monitoring to take place at appropriate intervals. Taking baseline measurements will determine how much time is expected to elapse between the detection of a fault condition and the actual failure point – known as “Lead Time to Failure” – which will determine the monitoring interval. For example, if a particular fault will cause the equipment to run incorrectly or fail within a few minutes, it cannot be monitored intermittently. As some faults occur progressively over a relatively long time while some have a negative impact within a matter of days, monitoring intervals must be set individually to allow sufficient time to react.
Following any maintenance actions, feeding back into the history record is essential to allow analysis of failures and assist in future diagnosis of faults, in much the same way as car owners record services and repairs in a log book. Monitoring intervals must be reviewed as the equipment ages or if the occurrence of faults seems erroneous, and maintenance tasks may need to be re-prioritised as a consequence of past servicing – for example if a component is changed the lubricant used may also change, which may impact on oil change schedules.
The benefits of switching to proactive, condition-based maintenance in preference to reactive, run-to-fail methods are wide-ranging. It can be applied to many types of equipment and components – from gearboxes and electric motors to turbines and generators – and applies to all failure profiles. As it can detect faults before failure it leads to long-term costs savings, allowing maintenance work to be planned around production schedules rather than causing disruptive downtime. Preventing a failure in the first place also eliminates much of the secondary damage which plagues facilities running reactive maintenance programmes and creates extra work for engineers.
However, in order to be implemented successfully, an initial time investment must be made in cost/benefit analysis, cataloguing and auditing equipment, and targeting the failure mode of each component to be monitored. Finally, there must be a reasonable “lead time to failure” for condition-based maintenance to be successful and, where equipment will fail within a very short time of developing a fault, other proactive methods of maintenance such as breakdown or planned/preventative maintenance or even designing out the fault, should be employed alongside the wider maintenance process.






I find it difficult to get from the text the difference between run to failure and breakdown maintenance. How is run to failure a reactive maintenance strategy while breakdown maintenance is a proactive maintenance strategy?